Solver Selector
AutoSearch
Solver name is “auto”.
- class flopt.solvers.auto_search.AutoSearch[source]
Auto Solver Selector
This automatically selects and runs solver according to the problem and settings.
from flopt import Variable, Problem, Solver # Variables a = Variable("a", lowBound=0, upBound=1, cat="Integer") b = Variable("b", lowBound=1, upBound=2, cat="Continuous") c = Variable("c", lowBound=1, upBound=3, cat="Continuous") prob = Problem(name="Test") prob += 2*(3*a+b)*c**2+3
Then, we use Solver(algo=”auto”) and solve.
solver = Solver(algo="auto") solver.setParams({"timelimit": 10}) prob.solve(solver, msg=True) >>> # - - - - - - - - - - - - - - # >>> Welcome to the flopt Solver >>> Version 0.5.4 >>> Date: September 1, 2022 >>> # - - - - - - - - - - - - - - # >>> >>> Algorithm: Scipy >>> Params: {'timelimit': 10}
See the log, you can see the Random algorithm is used for this problem. Executing .select(), we can check which solver will be select.
solver = Solver(algo="auto") solver.setParams({"timelimit": 10}) solver = solver.select(prob) print(solver.name) >>> Scipy
How solver is selected?
s section shows how solvers are selected in AutoSolver. For user-defined problems, AutoSolver uses two features for solver selection: the number of variables and the time limit. These features may be replaced in the future by better information of solving conditions.
We have created 200 training problems for each of the following problem types.
nonlinear
nonlinear with integer variables
ising
A training instance has a problem with k variables and a time limit t seconds, where k is randomly sampled from [2, 1000] and t is randomly sampled from [2, 120]. flopt solves the problem of instance using all available solvers with the time limit of instance, and finds the solver that performs the best for that training instance.
Then, we trains the multi class classification model for solver selection using this pair of training instances and the best solver. We used sklearn for training model. We split the data for training and validation, and adopt the model with the highest percentage of correct answers on the validation data.
The model after training is visualized as follows.
nonlinear
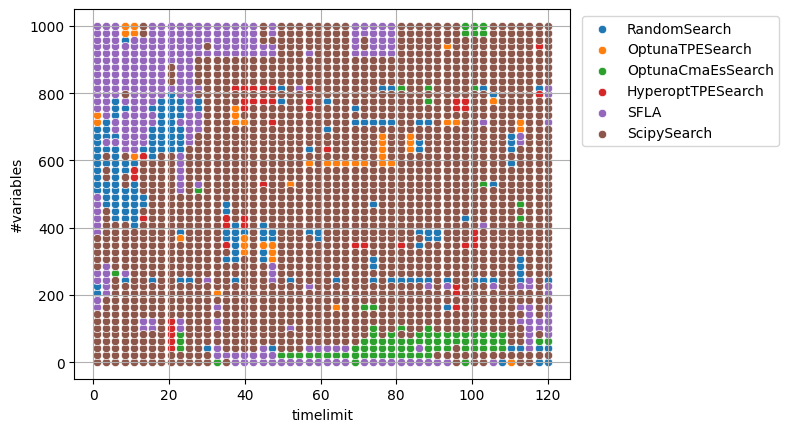
nonlinear with integer variables
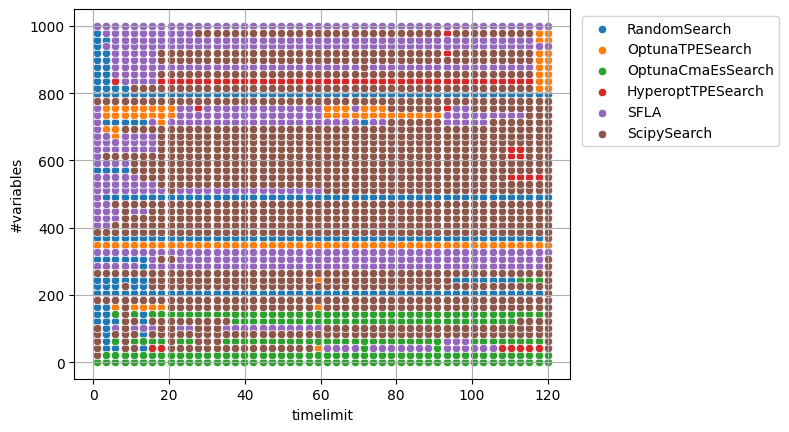
ising

The trained model is published on https://github.com/nariaki3551/flopt_trained_model/releases/tag/v0.5.5.0 and downloaded automatically when user use AutoSolver.
ScipyMilpSearch is used in the case of MIP, and ScipySearch will always be used in other case if the model cannot be downloaded.